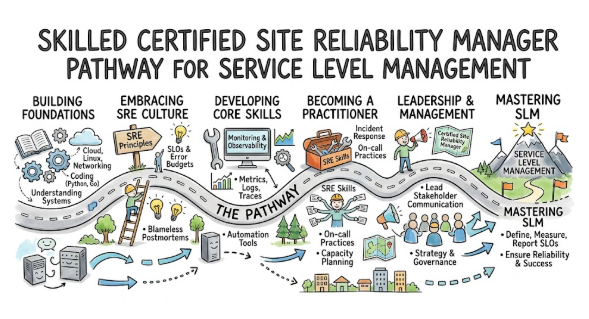
1. Introduction
Modern technology landscapes require software products to be highly available, scalable, and resilient. To achieve this, the gap between writing code and maintaining infrastructure must be bridged. Many organizations face immense pressure to ship features quickly while ensuring zero downtime. This tension often leads to team burnout and unstable production environments.
A structured framework is provided by professional certification pathways to address these exact operational challenges. Leaders are equipped with the knowledge needed to shift teams from reactive firefighting to proactive system planning. Technical engineering practices are successfully blended with strategic leadership methodologies.
2. What is Certified Site Reliability Manager?
The Certified Site Reliability Manager is a professional designation designed for individuals who oversee the health, performance, and scalability of distributed systems. It acts as a standardized credential confirming that a leader can align low-level infrastructure performance with high-level business goals.
Why It Matters Today
Reliability is now recognized as the most fundamental feature of any digital application. Without stable uptimes, even the most innovative software features become useless. Modern production environments run on complex cloud-native architectures, microservices, and containerized platforms. Managing these distributed setups requires specialized leadership. Managers must know how to govern technical risks, coordinate incident responses, and minimize system failures without stopping developer velocity.
Why Certified Site Reliability Manager Certifications are Important
Valuable validation is provided by these credentials in an increasingly competitive global IT market. The certification confirms that an individual is capable of managing production risks objectively using clear, data-driven engineering metrics.
- Standardized Frameworks: Teams are taught to speak a uniform language of reliability across development and operations.
- Operational Risk Mitigation: Financial and reputational damage caused by unexpected system outages is actively minimized.
- Business Alignment: Technical metrics are converted into clear business impact statements for executive stakeholders.
- Sustainable Workflows: On-call rotations and operational processes are optimized to prevent engineering burnout.
Why Choose SRESchool?
When pursuing a technical leadership credential, the choice of training provider directly impacts the practical value gained. SRESchool stands out as a globally recognized educational institute that specializes exclusively in reliability engineering and cloud-native management.
Instead of relying on dry, theoretical concepts, the entire curriculum at SRESchool is built entirely around production-focused learning and practical application. High-pressure production environments are closely simulated so candidates can test their knowledge against real-world failures. By offering structured, tiered certification paths, SRESchool ensures that every professional gains immediate, actionable skills that can be deployed into real enterprise workflows right away.
3. Certification Deep-Dive
The Certified Site Reliability Manager program is structured into clear, progressive tracks to accommodate professionals at various stages of their careers.
What is this certification?
This professional credential confirms a candidate's grasp of site reliability engineering philosophies from a strategic leadership standpoint. It validates that an engineer or manager can build reliable systems, design operational policies, and lead engineering teams effectively.
Who should take this certification?
This program is specifically designed for working software engineers, DevOps specialists, platform architects, cloud engineers, and technical engineering managers who want to transition into high-visibility site reliability leadership roles.
Certification Overview Table
| Track | Level | Who it’s for | Prerequisites | Skills Covered | Recommended Order |
|---|---|---|---|---|---|
| Core Reliability | Foundation | Aspiring Leads & Senior Engineers | Basic Cloud & DevOps Knowledge | SLIs, SLOs, Error Budgets, Toil Identification | 1 |
| Operations Lead | Professional | Engineering Managers & SREs | 3+ Years IT Experience | Incident Command, Post-mortems, Monitoring Stacks | 2 |
| SRE Automation | Professional | Technical Managers & Architects | Basic Scripting Knowledge | Toil Reduction, Infrastructure as Code, Automation | 2 |
| Executive Manager | Advanced | Directors & Aspiring CTOs | 5+ Years IT Experience | Organizational Design, FinOps, SRE Culture | 3 |
| Incident Management | Advanced | Crisis Leads & Production Heads | Core SRE Knowledge | Resilience Engineering, Stakeholder Communication | 3 |
Skills You Will Gain
- Service Level Governance: Proficiency in defining, measuring, and tracking Service Level Indicators (SLIs) and Service Level Objectives (SLOs).
- Error Budget Management: Ability to utilize error budgets to drive data-backed software release decisions.
- Toil Reduction: Expertise in identifying repetitive, manual tasks and implementing automation strategies to eliminate them.
- Incident Command Mastery: Structured coordination of multi-team responses during major distributed system outages.
- Blameless Culture Cultivation: Frameworks for conducting productive, non-punitive post-mortems to discover systemic root causes.
Real-World Projects You Should Be Able to Do
- Reliability Dashboard Engineering: Build a centralized monitoring dashboard that visualizes real-time SLI metrics for a microservices application.
- Error Budget Policy Drafting: Establish an official error budget agreement between development squads and business stakeholders.
- Toil Automation Engine: Create custom automated scripts or workflows to replace a manual, error-prone system backup process.
- Incident Response Drill Simulation: Design and execute a theoretical disaster recovery plan and a multi-region failover strategy for an enterprise database.
Preparation Plan
7–14 Days Plan
Focus is placed strictly on core SRE vocabularies and foundational pillars. The official glossary must be studied carefully. Time should be spent mastering the precise differences between SLIs, SLOs, and SLAs.
30 Days Plan
Foundational course modules are systematically completed. Practical application is practiced by drafting basic alerting rules and reviewing case studies of historical engineering failures. Mock exams are utilized to test conceptual knowledge.
60 Days Plan
Deep-dive simulations are performed. Concepts are implemented in a localized sandbox environment. Advanced architectural patterns are studied, and community discussion forums are engaged with to review enterprise organizational change management models.
Common Mistakes to Avoid
- Focusing Only on Tooling: Tools like Kubernetes or Prometheus change over time, but core reliability principles remain constant. The underlying methodology must be prioritized over specific software.
- Setting Unrealistic SLOs: Aiming for 100% uptime is mathematically impossible and prohibitively expensive. Achievable targets must be set based on user needs.
- Ignoring the Cultural Aspect: SRE is as much about human psychology and culture as it is about software code. If the engineering culture remains blame-oriented, automation cannot fix system deficiencies.
- Neglecting Toil Measurement: Manual tasks must be measured and quantified accurately before they can be effectively automated out of existence.
Best Next Certification After This
Same-Track
- Professional Site Reliability Manager: A deeper technical management credential focused on complex multi-cloud operations.
Cross-Track
- Certified DevOps Engineer: Expands expertise into continuous delivery pipelines and deployment orchestration.
Leadership / Management
- Technical Team Lead Foundation: Focuses on people management, conflict resolution, and soft skills needed for engineering leaders.
4. Choose Your Learning Path
To help professionals align their training with specific career goals, six distinct, structured pathways have been outlined below.
[Your Current Background]
│
├─► DevOps Pathway ───────► (Focus: Release Velocity + Core Stability)
├─► DevSecOps Pathway ────► (Focus: Vulnerability Patching + Resilience)
├─► Pure SRE Pathway ─────► (Focus: Latency, Saturation + Deep Automation)
├─► AIOps/MLOps Pathway ──► (Focus: Data Pipeline Health + Model Telemetry)
├─► DataOps Pathway ──────► (Focus: Data Flow Validation + Storage Uptime)
└─► FinOps Pathway ───────► (Focus: Cloud Spending Audits + Resource Tuning)
DevOps Pathway
This path is tailored for engineering teams looking to introduce strict stability metrics into high-velocity development pipelines. The transition from pure continuous integration to reliable, sustainable release management is supported.
- Best For: Build and release engineers, deployment specialists, and systems administrators.
DevSecOps Pathway
Security vulnerabilities are treated as a severe form of technical debt that directly impacts availability. Security practices are tightly integrated into the site reliability management lifecycle.
- Best For: Cloud security analysts, security engineers, and compliance officers.
Site Reliability Engineering (SRE) Pathway
Deep mechanics of large-scale distributed architecture are explored. Advanced monitoring, capacity planning, and systemic error handling are prioritized to ensure constant uptime.
- Best For: Dedicated SRE individual contributors, infrastructure engineers, and systems architects.
AIOps / MLOps Pathway
Focus is placed on the infrastructure and automated pipelines that power artificial intelligence models. Telemetry and automated response mechanisms are used to manage alerts across high-data modern environments.
- Best For: Machine learning engineers, AI infrastructure leads, and data science operations managers.
DataOps Pathway
Reliability concepts are applied directly to enterprise data storage, transformations, and analytics networks. Data pipeline degradation is successfully prevented before it impacts end-user applications.
- Best For: Data platform engineers, database administrators, and big data specialists.
FinOps Pathway
Technical cloud infrastructure health is balanced with fiscal responsibility. Teams are trained to optimize resource allocations and cloud-spend budgets without degrading performance or reliability metrics.
- Best For: Infrastructure managers, cloud cost optimization analysts, and cloud architects.
5. Role → Recommended Certifications Mapping
Career advancement is accelerated when credentials match day-to-day professional responsibilities. The table below maps common engineering roles to their ideal certification points.
| Current Professional Role | Ideal Recommended Certification Target |
|---|---|
| DevOps Engineer | Certified Site Reliability Manager Foundation |
| Site Reliability Engineer (SRE) | Professional SRE Management Track |
| Platform Engineer | Advanced Platform Strategy Track |
| Cloud Engineer | Core SRE Foundation & Automation |
| Security Engineer | DevSecOps Specialization Track |
| Data Engineer | DataOps & Reliability Foundation |
| FinOps Practitioner | FinOps for SRE Managers |
| Engineering Manager | Professional SRE Leadership |
6. Next Certifications to Take
Continuous professional development ensures long-term career resilience as technology ecosystems evolve.
One Same-Track Certification
The Advanced Reliability Strategy credential can be pursued next to expand skills in designing geo-distributed architectures and enterprise failover policies.
One Cross-Track Certification
The Certified Cloud Architect certification can be taken to deepen expertise across multi-cloud service models, networking layers, and hybrid enterprise integrations.
One Leadership-Focused Certification
The Engineering Manager Professional program can be chosen to master advanced organizational design, tech-talent recruitment strategies, and corporate technology budgeting.
7. Training & Certification Support Institutions
Several reputable professional bodies offer training structures and support ecosystems to help candidates prepare successfully for reliability certifications.
DevOpsSchool
A premier learning platform known for its comprehensive, deep-dive catalogs across modern cloud methodologies. Extensive training resources, live interactive labs, and real-world implementation projects are provided to global learners.
Cotocus
Specialized training consultations are provided by this entity, focusing heavily on modern enterprise infrastructure migrations. Customized workshops designed to train corporate engineering squads in containerization and modern production architectures are regularly delivered.
ScmGalaxy
A vast community hub and educational repository centered entirely around configuration management and software supply chain automation. In-depth technical articles, video tutorials, and peer mentoring forums are offered to help candidates learn modern tools.
BestDevOps
Structured, self-paced learning pathways built exclusively for working professionals are provided here. Practical, bite-sized training modules focused on the immediate application of operations principles within modern software teams are delivered.
devsecopsschool.com
Educational efforts are focused strictly on the intersection of system security and delivery automation. Specialized training curriculums are offered to help teams embed security guardrails seamlessly into automated software development lifecycles.
sreschool.com
The primary, dedicated digital educational institution focused entirely on reliability engineering disciplines. A complete, tiered ecosystem of official courses, certifications, and hands-on production environment sandboxes is hosted here.
aiopsschool.com
Training programs are directed toward the application of machine learning solutions within standard IT operations. Modern techniques for automated anomaly detection, alert filtering, and predictive system maintenance are taught.
dataopsschool.com
Structured training environments are provided to manage data pipelines as software products. The certification courses ensure data delivery systems remain highly available, accurate, and completely resilient under high processing volumes.
finopsschool.com
Curriculums are built specifically to bridge cloud engineering actions with corporate financial accountability. Strategic frameworks needed to manage, audit, and optimize cloud infrastructure spend across large enterprises are provided.
8. FAQs Section
General & Strategic FAQs
What is the overall difficulty level of the reliability management program?
The foundational tracks are moderately accessible for individuals with basic operations exposure, whereas the professional and advanced tracks are highly challenging and require a deep understanding of production workflows.
How much time is typically required to complete the preparation?
Depending on prior hands-on experience, a dedicated commitment of 30 to 60 days is generally sufficient to master the curriculum and pass the evaluations.
What are the primary prerequisites for enrolling in the course?
Familiarity with cloud computing concepts and basic DevOps development workflows is required, along with a few years of IT experience for the advanced tiers.
What is the recommended certification sequence to follow?
Candidates should start with the Core Reliability Foundation, progress through the Operations or Automation Professional tracks, and conclude with the Executive Management certifications.
What long-term career value is delivered by this credential?
Professionals are successfully transformed from reactive individual contributors into strategic leaders who are qualified to lead high-paying, high-visibility infrastructure teams.
Which specific job roles are unlocked after graduation?
Graduates routinely step into roles such as SRE Team Lead, Platform Director, Infrastructure Manager, Production Operations Head, or Engineering Manager.
How does this framework address the issue of engineer burnout?
Managers are taught to measure and minimize manual toil while establishing clear error budgets that prevent development teams from overworking systems.
Can these management principles be deployed inside legacy on-premise data centers?
Yes, the underlying philosophies of service level management and blameless post-mortems apply universally to any infrastructure, regardless of whether it is hosted on cloud or on-premise systems.
What is the core operational metric emphasized throughout the program?
Mean Time to Recovery (MTTR) and Service Level Objective (SLO) compliance are prioritized heavily over non-actionable vanity uptimes.
How are practical engineering skills evaluated during the testing phase?
Scenario-based case studies and practical assessments are utilized to check how a candidate coordinates responses to complex, simulated production outrages.
Why is organizational cultural change prioritized so heavily in the modules?
Technical tools fail if the surrounding culture remains siloed, meaning long-term reliability requires shifting the business mindset toward shared operational ownership.
Does the program cover the financial aspects of running large cloud infrastructures?
Yes, specialized modules within the advanced tracks address cloud budget governance, asset optimization, and strategic resource allocation.
Certified Site Reliability Manager FAQs
1. How does the Certified Site Reliability Manager framework differ from standard DevOps approaches?
DevOps focuses broadly on breaking down siloes between development and operations pipelines, while this framework provides concrete, mathematical engineering practices to run production systems reliably.
2. What role do Service Level Objectives play within this leadership curriculum?
SLOs serve as the foundational decision-making baseline, providing an objective data metric that balances the demand for rapid feature shipping with system stability.
3. How are manual operational tasks classified and handled under this standard?
Repetitive, non-creative manual tasks are classified as operational toil, and managers are taught to limit this work to less than 50% of a team's total capacity through automation.
4. What specific incident coordination frameworks are introduced during the training?
A structured incident command system is established, where distinct roles for operational command, communications, and technical investigation are clearly assigned during system failures.
5. How does this credential assist in building and recruiting better tech teams?
Clear rubrics are provided to evaluate systemic skills, allowing leaders to hire engineers who understand system architecture, automation, and diagnostic processes.
6. How is post-incident learning managed by a certified professional?
A strict blameless post-mortem process is facilitated, focusing entirely on finding technical and procedural bugs rather than finding human culprits to blame.
7. In what way does this certification enhance stakeholder communication?
Technical infrastructure issues are successfully translated into financial risks and business outcomes, enabling productive conversations with executive directors.
8. Is continuous professional re-certification required to maintain the credential?
Yes, active engagement with updated materials, cloud-native case studies, and modern architecture reviews is required periodically to keep the designation current.
9. Professional Testimonials
The structured frameworks for managing error budgets provided immediate operational clarity. System performance metrics are now successfully aligned with our core business objectives.
— AnanyaA major shift in how team workflows are handled was triggered by the toil reduction methodologies. Manual overhead was successfully cut by 40% within a few months of implementation.
— DavidDeep tactical confidence was gained through the incident command simulations. Communication silos across our global engineering offices have been completely eliminated.
— RajeshThe blameless post-mortem models have completely transformed our operational engineering culture. Outages are now treated as valuable learning opportunities rather than sources of blame.
— SarahClear career direction was delivered by the strategic management tracks. The transition from a senior technical contributor to an infrastructure director was navigated seamlessly.
— Vikram
10. Conclusion
Navigating the complexities of modern, distributed IT environments requires engineering leadership that goes far beyond traditional administrative roles. The Certified Site Reliability Manager certification provides a definitive, production-focused pathway that enables professionals to successfully balance rapid continuous software delivery with absolute systemic stability.
Long-term career resilience is achieved by mastering these specialized data-driven operational frameworks, turning engineers into critical assets for the global technical market. Long-term operational growth and personal advancement are guaranteed when technical educational training and strategic certification planning are prioritized.
Top comments (0)